Preface
All of us are familiar with the idea of anonymizing datasets to get rid of personally-identifiable information, in order to enable data mining while preserving (as much as possible) the privacy of the people whose data was collected. The basic idea is to modify names, ID numbers (Social Security Number in USA), home addresses, birthdays, IP addresses and similar information. Sometimes, one needs to get rid also of information about age/gender/nationality/ethnicity.
This method was subjected to a lot of research and it is easy to find, with the help of search engines, relevant papers and articles. See Bibliography for examples.
However, there is also another transformation of datasets. Unlike anonymization, as described above, this transformation is not about privacy preservation. It is about hiding the nature of the data being processed. Lacking a better term, we’ll use the term anonymization also for this transformation.
One possible application for this kind of anonymization is when one develops a revolutionary model for predicting the future behavior of the stock exchanges of the world by following various economic indicators and other publicly available time-dependent data sources.
In such an endeavor, the developer typically has gathered a lot of data, and wants to use it to train his revolutionary machine learning model. Since he cannot afford to build his own data center, he rents a lot of computing power in one of the cloud providers.
However, he does not want to take the risk of an unscrupulous employee of the cloud provider stealing his secret data or model and using it for his own benefit. He also wants to reduce the damage if a black hat hacker breaks into his rented computers.
Some users might want to process information, which interests governments such as the Chinese government. Those governments have the resources to break into cloud computers.
The classical way to mitigate such risks is to encrypt/recode/scramble (henceforth, I’ll refer to all those operations as encryption) the data being uploaded to the cloud. However, this encryption must be done in such a way that the data is still suitable for training the model. In addition, when running the model for making a prediction, the raw model’s results need to be generated in an encrypted form, for decryption in the developer’s on-premises computer/s (to which I will refer as a workstation henceforth). From this point on, we’ll use the terms anonymization and encryption interchangeably.
When looking for relevant research on the second kind of anonymization, I did not easily find relevant information. It motivated me to write this article.
Glossary
The following symbols are described in order of their appearance in text.
-
 : the transfer function of a machine learning system.
: the transfer function of a machine learning system. : the argument of – the data used by a machine learning system to make a prediction.
: the argument of – the data used by a machine learning system to make a prediction. : the
: the 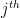 element of .
element of . : the value of
: the value of 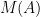 i.e. the prediction that the machine learning system makes when presented with data .
i.e. the prediction that the machine learning system makes when presented with data .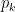 : the
: the 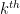 element of .
element of . : the identity function. For all
: the identity function. For all  ,
,  .
. is the inverse of
is the inverse of  , for any function : for all relevant ,
, for any function : for all relevant , 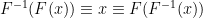 .
.- Functional composition: for all relevant ,
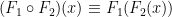 . For example,
. For example,  .
.
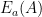 : a function which encrypts the argument . Its inverse is denoted by
: a function which encrypts the argument . Its inverse is denoted by  , which decrypts
, which decrypts 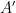 , an encrypted version of the argument .
, an encrypted version of the argument .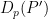 : a function which decrypts the encrypted prediction
: a function which decrypts the encrypted prediction  . Its inverse is denoted by
. Its inverse is denoted by  , which encrypts the prediction .
, which encrypts the prediction .
Architecture of machine learning systems
A machine learning system is used to approximate a function , which makes a prediction (or classification or whatever) , given the n-tuple which packs together several argument values:
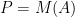
where:
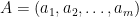
is the argument, and
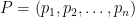
is the prediction.
The values of the argument and of the prediction can be of any data type and they are not limited to scalars. This is why a n-tuple notation is used rather than a vector notation.
Examples of machine learning system applications:
- Picture classification. When presented with a picture of an animal, the system would tell how likely is the animal to be a dog, a cat or a horse. The system is trained by presenting it several pictures together with a label identifying the animal shown in the picture.
- Prediction of the next few values of a time series, such as the numbers which describe the weather at a particular location. The system is trained by using relevant historical information.
Machine learning systems are sometimes implemented using neural networks. Neural networks have the property that a sufficiently large neural network can be trained to approximate any function, which meets certain reasonable conditions.
A machine learning system is trained to implement a good approximation of the function by processing several 2-tuples of  , which associate each prediction – the desired value of the function (which is usually a n-tuple) – with the corresponding argument value (which is usually a n-tuple).
, which associate each prediction – the desired value of the function (which is usually a n-tuple) – with the corresponding argument value (which is usually a n-tuple).
The training process is very computationally intensive, so people often resort to cloud computing facilities, as said above.
Architecture of anonymized machine learning systems
When an user does not want to let the cloud provider know what he is doing, one possible approach is to train the model using encrypted data streams, so that the model’s outputs are encrypted as well. The data streams are encrypted on the user’s workstation. The workstation is used also to decrypt the model’s predictions.
The whole system can be described using the following formulae.
Original system:
We add identity functions before and after :
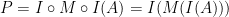
The next step is to decompose the identity functions into pairs of a function and its inverse. The functions being used perform encryption and decryption.
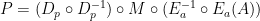
where encrypts the argument and decrypts the prediction .
Now we rearrange parentheses as follows:
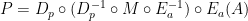
Now the system can be decomposed into three parts, which perform the following operations:
- Encrypt the argument :
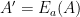
- Actual encrypted machine learning system:
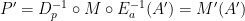
- Decrypt the encrypted prediction :
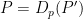
where and are the encrypted argument and prediction respectively.
The functions and need to be invertible, as their inverses are part of the function being approximated by the learning machine model 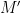 , which is the second part of the system, and is the one actually run on the cloud provider’s computers.
, which is the second part of the system, and is the one actually run on the cloud provider’s computers.
The first and third parts are implemented on the user’s workstation. The typical implementation relies upon keys and scrambling formulae.
Two more requirements are:
- The machine learning model
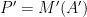 is to be implemented using a technology, which is sufficiently sophisticated to embed also nonlinear and invertible functions in the loss function used to evaluate it.
is to be implemented using a technology, which is sufficiently sophisticated to embed also nonlinear and invertible functions in the loss function used to evaluate it.
- There is sufficient training and validation data to train the model, which embeds including nonlinear invertible functions.
Types of data
When dealing with anonymization of data, one has to consider separately each of the following data types.
- Variable names
- Numerical variables
- Ordinal variables
- Categorical variables
- Time based variables
Variable names
Variable names are used for naming the various variables which are part of the argument and prediction of the machine learning model. They are used for inspecting the argument’s data streams and for retrieving relevant parts of the model’s prediction.
Of course, the cloud provider should not be exposed to the true names of the variables.
Variable names can be converted into meaningless strings. For example, by using standard password scrambling algorithms, such as salt+md5sum.
The user’s workstation would have tables for mapping among the true variable names and the names used by the model and databases in the cloud.
Numerical variables
Numerical variables can be transformed using invertible functions.
Also, if the argument has several numerical elements (including time based elements), one could treat them as a single vector and transform it using an invertible matrix.
Mathematically, it could look as follows:
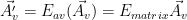
where:
 is the restriction of A to numerical variables.
is the restriction of A to numerical variables. is the encrypted version of.
is the encrypted version of.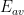 is the argument’s encryption function, restricted to numerical elements of the argument .
is the argument’s encryption function, restricted to numerical elements of the argument .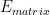 is an invertible transformation matrix.
is an invertible transformation matrix.
Invertible scalar functions could be applied to 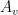 ‘s elements before and after the matrix transformation.
‘s elements before and after the matrix transformation.
If the argument has also an element, which is a categorical variable, one could use a different transformation for each value of the categorical variable.
Ordinal variables
The values of the ordinal variables could be permuted. The learning model will implicitly embed the inverse permutation.
Categorical variables
Shuffling categories is not enough, because categories could be identified by their frequencies (like application of Zipf’s law to decrypting substitution ciphers).
The following approach is probably not universally applicable.
Categories could be anonymized by splitting a frequently occurring category into several subcategories. The learning model will give a different prediction for each subcategory. The different predictions will have to be somehow combined in the user’s workstation.
This approach also requires the model to be formulated in such a way that the final prediction can be derived by combining the predictions corresponding to the subcategories of split categories.
Time based variables
When anonymizing time based variables, one needs to transform the argument to hide any dependence it has upon weekly, monthly, seasonal or yearly cycles. One needs also to hide dependencies upon well-known events, such as volcano eruptions or rising 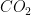 concentration in air.
concentration in air.
Otherwise, it would be possible to identify dates by looking for correlations with well-known timings.
One possible way to hide those dependencies is to apply an ARIMA forecasting model to the argument.
Bibliography
The following articles are about getting rid of personally-identifiable information in order to preserve privacy.
-
-
- https://en.wikipedia.org/wiki/Data_anonymization
- Generalization.
- Perturbation.
- http://blog.datasift.com/2015/04/09/techniques-to-anonymize-human-data/
The methods proposed by this article could interfere with machine learning, except for sufficiently small perturbations.
- https://www.elastic.co/blog/anonymize-it-the-general-purpose-tool-for-data-privacy-used-by-the-elastic-machine-learning-team
- Suppression of fields.
- Generation of semantically valid artificial data (such as strings). There is a Python module – Faker – which is good for faking names, addresses and random (lorem ipsum) text.
- The methods, mentioned in this article, cannot anonymize numeric data.
- https://docs.splunk.com/Documentation/Splunk/7.2.3/Troubleshooting/AnonymizedatasamplestosendtoSupport
Anonymization of data such as usernames, IP addresses, domain names.
- https://www.oreilly.com/ideas/anonymize-data-limits
Human data cannot really be anonymized.
- https://www.intel.co.kr/content/dam/www/public/us/en/documents/best-practices/enhancing-cloud-security-using-data-anonymization.pdf
Several methods for anonymizing data such as identifying information of humans, IP addresses, etc:
- Hiding
- Hashing
- Permutation
- Shift
- Enumeration
- Truncation
- Prefix-preserving
- https://ieeexplore.ieee.org/abstract/document/6470603
Usage of MapReduce to anonymize data.
Addendum
After finishing the first draft of this post, I was informed of the following.
Credits
I wish to thank Boris Shtrasman for reviewing a draft of this post and providing a lot of feedback. Of course, any remaining inaccuracies in this post are my sole responsibility.
Like this:
Like Loading...

